Common statistical or data mining methods cannot cope with unstructured data (e.g., texts, images or videos) and the business analyses are often based on the structured information only. The unstructured sources are thus omitted even though they usually contain important insights. The DATLOWE solution can help to process the text data, so that they can be analyzed by classic statistical algorithms.
We closely collaborate with Faculty of Mathematics and Physics at Charles University in Prague and we use their latest results of research on computational linguistics and ontology engineering.
Lately, we focus on projects in customer analytics, healthcare and automated processing of legal documents. In all of these areas people are struggling with huge amount of text data: emails and online reviews from customers, medical reports or all sorts of contracts. In this paper, we will shortly describe our legal documents pipeline.
Analyzing legal documents
Law or real estate companies manage tens of thousands of cases, which contain related legal documents (usually some contracts or licenses, their amendments, invoices, blueprints, letters, etc.). Currently, looking up some specific information is almost impossible. Our goal is to automate the processing of these cases: to categorize each document and to extract the most critical data about contract subject, mentioned parties, terms or fees. Information extraction along with full text search would enable the owners to filter their documents and easily perform other reporting tasks and analyses.
OCR
The documents are usually only scanned PDFs so we start with OCR engine to get them into machine readable form. We also collect information about formatting and positions of pages, paragraphs, pictures and tables as the side product of OCR analysis.
Linguistic analysis
Then we run our linguistic tools, which include state-of-the-art language models, on machine readable texts from OCR. The most essential part is lemmatization, which transforms the words into its base forms – lemmas. The base form of nouns is nominative of singular, the lemma of verbs is the infinitive etc. This is superior to stemming, which simply trims prefixes and suffixes.
Feature engineering
After linguistic analysis, the text data are stored in a structured table (one row for each lemma) and can be further transformed into document term matrix – pivot table where documents are in rows, lemmas are in columns and cells contain (normalized) frequencies. We also add semantic features (e.g., frequencies of mentioned dates, personal names, amounts, towns), which are products of our annotation application.
We build another set of attributes from document layout. We compute number of pages, number of characters per page, absolute and relative page proportions, absolute and relative areas of paragraphs, tables and pictures and many other indicators. Relationships between some of these variables and the type of the document is obvious even without any data mining technique. E.g., letters are usually shorter than contracts and reports contain more pictures than contracts.
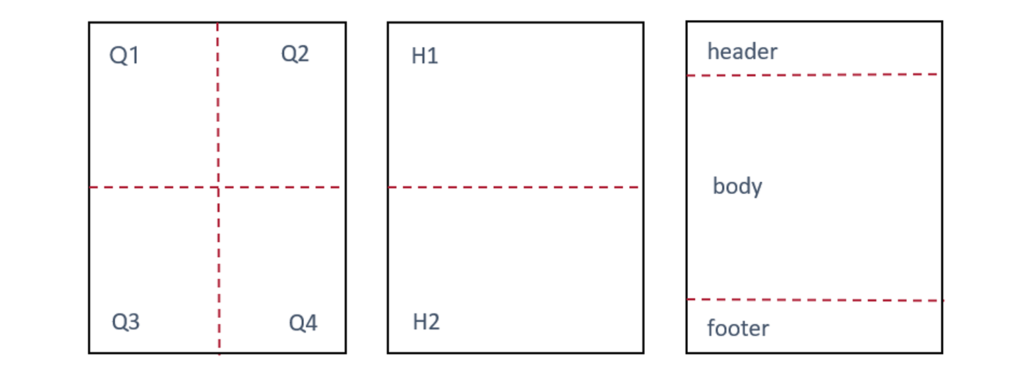
We also create several page sectors by dividing each page to quarters, halves and header, body and footer (see figure 1). We then observe our attributes per whole page and (when it is possible) per these sectors. This is based on typical layout of the documents, e.g., business letters usually contain address in Q1 sector on the first page.
This means that we create more than 1300 variables based solely on layout and we add them to the document term matrix. Document term matrix by itself is usually large and sparse and therefore feature selection can’t be omitted before following analysis to prevent overfitting.
Both of our tasks (document and paragraph classification) belong to supervised learning, so we need target variables. We use manually annotated data (thousands of documents) to create our models and we train separate model for each business case as we believe that each data set is unique and some general model wouldn’t provide required performance.
Categorizing documents
Data set is aggregated on document level (one row per document) and divided into training, testing and evaluation partitions. Document type attribute from manually annotated data serves as the target variable. Document type is nominal variable having a number of categories (e.g., contract, plan, report) and each document belongs to exactly one of them. Therefore, we use multinomial classification methods.
We train several classification models (e.g., random forests, gradient boost machines, AdaBoost) and apply ensemble modeling. We tune our hyperparameters on the testing data and keep the evaluation data intact for final performance assessment.
The model performance depends on the data set, number of categories and selected machine learning method, however it usually achieves accuracy over 0.95 and sensitivity over 0.9 for most of the categories. It is common, that the most important variables are mixture of lemmas, semantic features and layout variables (so the target significantly depends not only on the text, but on the layout of the document as well).
Categorizing paragraphs and information extraction
During the information extraction phase, we try to highlight specific text chunks about parties, options, clauses and other mentioned facts.
When analyzing the paragraphs, each paragraph can belong to more than one category, therefore we use several binary classifiers (one per each paragraph type). Data set is aggregated on paragraph level and the training procedure is similar to the one for categorizing whole documents.
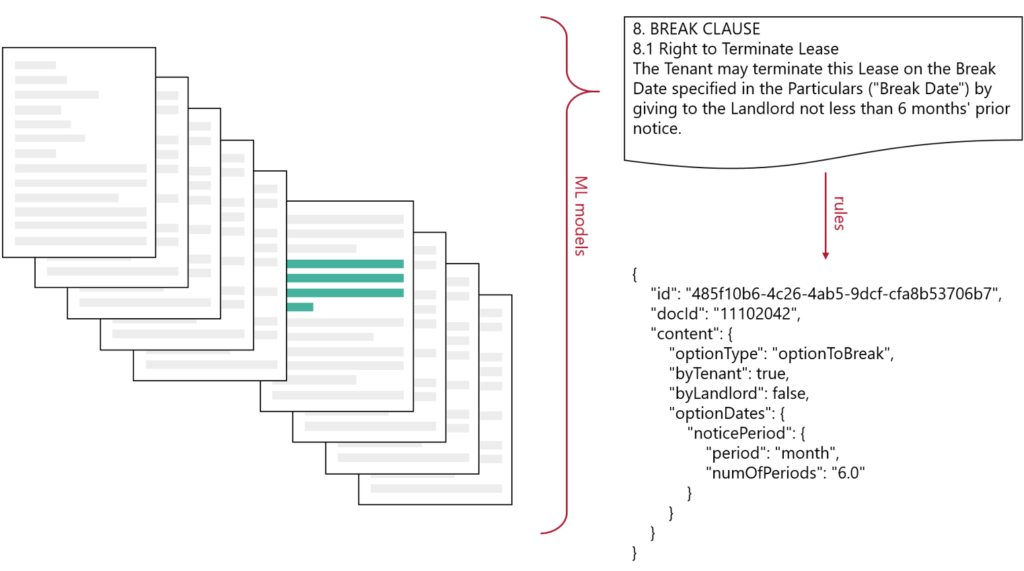
After we preselect paragraphs (e.g., all the paragraphs that are likely to contain options), we apply sets of rules to determine the details (e.g., what is the option type, can it be exercised by the landlord or tenant, what are the dates). These can be simple regular expressions or very complex business rules.
Deployment
At the end, we implement our models, so they can be used for batch or real time scoring of newly arrived documents.
We usually display the results in our application, which can be used to browse the processed documents easily, to check the details prefilled by machine learning models (and to correct them when the scoring isn’t exact) or to create advanced reports.